Hackle's blog
between the abstractions we want and the abstractions we get.
For me this blog is not just some place I post my learnings and ideas, but also somewhere I can put them into practice. Here is a brief overview of what I used for this blog, and some notable facts.
Like many others I have had the Rust envy for a long time. Came the holiday season recently, I eventually overcome my laziness and started chipping away on a rewrite of this blog.
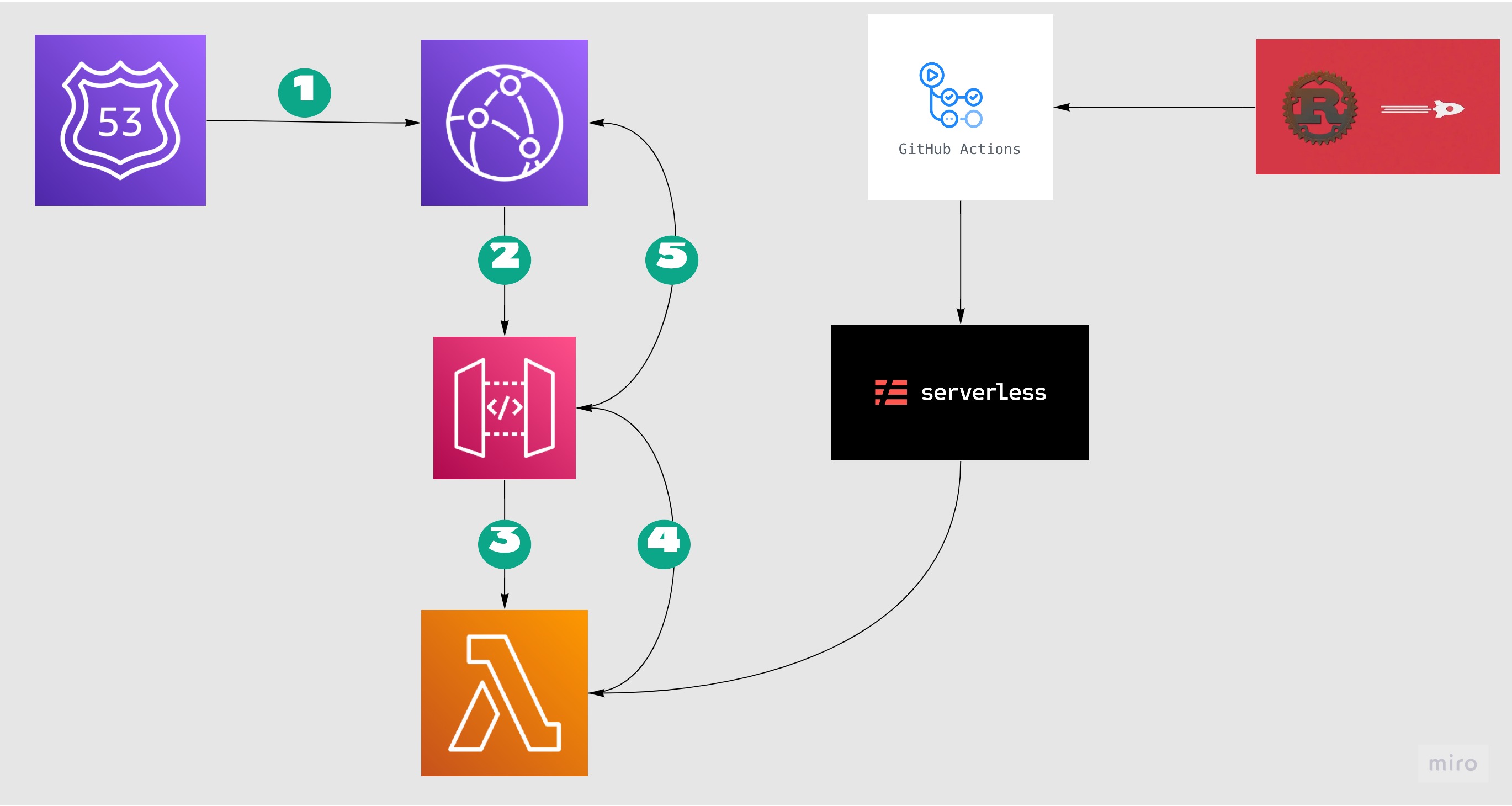
Rust turned out to be an absolute delight but I should have expected that the infrastructure and ops concerns took up way more time than I would have liked. However it is now done and I want to put an architecture diagram here.
Points of interest,
aws-invocationurl.../prod.provided.al2 which stands for Amazon Linux 2, a docker image to build the executables upon.Tiredness with manually deploying this blog and keeping AWS credentials on my machine led me to bite the bullet and adopt GitHub Actions for building and publishing. I was pleasantly surprised how flat and smooth the learning curve is and I really appreciated the open-source integrations available for various aspects of the pipeline. Even for building a Haskell application. Sure it's a sign of prime time to come?
Upon reading The ReaderT design pattern I got itchy hands, therefore a refactor was done to the very simple code base. The main benefit is the environment values / operations are made explicit, and the IO monad is surfaced only on the top layer. A happy refactor.
I've been procrastinating on switching this blog to using aws-lambda-haskell-runtime. Compared to serverless-haskell, It has no dependency on node, and feels more "native" to me.
Also because of the dependency on node, GitHub sends me warnings once in a while about out-dated packages that exposed vulnerabilities. Just a bit annoying.
On the other hand I tried to create a custom lambda runtime in Idris, and actually got it running, except once in a while I would get a SIG_FAULT and I had to give up. To me coding IO heavy stuff in Idris is not much different to Haskell, just with less libraries to use and needed much hacking.
As it turned out, aws-lambda-haskell-runtime is a joy to use. The documentation is succinct but on point. The only hiccup I had was trying to do stack build on my MacBook, and couldn't overcome a linker error. A bit of googling revealed it's kind of a no-go when (static?) linking is a concern. Then I just did stack build --docker and all was good.
Before removing serverless-haskell I realised I still needed the types for the Api Gateway and why write more code if I already have it for free? So I let both libraries live together happily.
To make things even easier, the serverless framework is quite up-to-date when it comes to support for custom runtime. Seriously, I should have looked into this much sooner!
This blog is based on the excellent serverless-haskell framework, which enables me to utilise the power of AWS Api Gateway + Lambda with code written in Haskell. Nothing wrong with any other languages but Haskell is what I am learning at this moment (and have been for a while now).
One thing that I wasted too much time on, is trying to set up the stack for development on Windows. I got really close - but never quite there. There was some indirect dependency with the word "unix" in its name that refused to work. Maybe the name itself strongly hints that it's not meant for Windows. It's actually not easy for me to take this fact in as I use Windows a lot. A shame it's treatment is as if it's a second-class citizen when Haskell is concerned. (Actually this happened again when I tried with Idris. Sigh.)
Instead I got everything working within an hour or so in Ubuntu. No major problems. (As a matter of fact, even quicker on a MacBook...)
Honestly I am still confused as to where and when to or not to use the Haskell Platform. There seems to be a gap between how Stack works and how the Platform advocates.
In this case though, stick with Stack is easier - only meaningful change I need to make is to set resolver: lts-9.1 in the stack.yaml file. "stack install" took care of everything.
Yes that's right - unfortunately. Due to some strange cock-up with particular versions above GHC 8.1+, GHC-Mod will end up eating up a lot of memory, and for me, eventually freeze up my Ubuntu virtual machine.
I then switched to GHCID, much lighter, running on command line, but man that makes life much easier.
github markdown styling is used.
Currently building HTML markups and parsing markdown are both done on server side using Blaze and Text.Markdown. Both pretty intuitive.
For syntax highlighting of code blocks in various languages, prism turned out to be handy. I did use the Haskell styling also for Idris (instead of tagging Idris code block as Haskell) - works like a charm.
Under the hood, serverless-haskell wraps an executable, which in theory can be written in language, and mostly certainly Idris?
This can be simply a matter of porting some of the code into Idris. Considerations are,
Considering the amount of work, it seems reasonable to start lean. My ideas are:
So watch this space for lambda-idris.